As a technologist, I’m growing concerned about the often rushed adoption of machine learning techniques in software and the impact on underrepresented groups. We cannot simply brush off the risks of biases in models and datasets. I’m neither a mathematician nor a sociologist, I’m a practitioner. By providing very clear and repeatable examples of biases, I hope that this post will help bring awareness to the reader on what academia and industry practitioners ought to do.
📎 TL;DR
Biases can be found at every stage of a machine learning process. Practitioners must change their use of publicly distributed large datasets and models. One cannot build a responsible product without understanding the risks and biases that come with it.
- Adopt responsible AI practices and ensure proper documentation of your machine learning models with systems like Model Cards and Datasheet for datasets.
- Corporate policies (security, governance, and business ethic) should define the boundaries of machine learning practices, especially when using large third-party datasets or models, to make transparent any risks, tradeoffs, and how to mitigate identified bias.
I was inspired to write this post after the recent firing of Dr. Timnit Gebru, a Staff Research Scientist and Co-Lead of the Ethical Artificial Intelligence (AI) team at Google. Dr. Timnit Gebru was one of the very few Black Women at Google Brain. Also, given the recent reports of Google telling its scientists to ‘strike a positive tone’ in AI research - documents, there is enough to be concerned about the lack of transparency and candor in the industry.
When talking about social stigmas, and especially racial stigmas of black communities, I found the writings and interviews of Glenn Loury quite insightful. Glenn Loury became the first black tenured professor of economics in the history of Harvard University.
An important consequence of racial stigma is “vicious circles” of cumulative causation: self-sustaining processes in which the failure of blacks to make progress justifies for whites the very prejudicial attitudes that, when reflected in social and political action, ensure that blacks will not advance. [..] The original negative stereotype is then reinforced [..] We will not necessarily find evidence of racial stigma by searching government statistics for instances of racial discrimination. The effects of stigma are more subtle, and they are deeply embedded in the symbolic and expressive life of the nation and our narratives about its origins and destiny.
Racial stigma and its consequences Glenn C. Loury is Professor of Economics, Brown University
Given the large adoption of machine learning in our day to day life, there is a higher risk to simply reinforce these vicious circles and amplify racial discrimination, willingly or not. How so? A lot of practitioners seems to put the whole magic of machine learning under the algorithm umbrella and won’t take any responsibility for any bad outcomes. They just want to go for the wow effect after some successful predictions to get their next career promotion. Even though the probability of something to happen or be doesn’t make it a reality, Probability is Not Predictability. Rushed software development may lead to insensitive outcomes or people’s lives being damaged.
As a software engineer, if you are tasked to build a software product to decide who gets a grant to get into an institution and decide to use certain features or data that include social bias, you may be reinforcing those stigmas and may have created a system close to redlining.
Educating Product and Engineering teams on the risks of software that depend on Machine Learning can help mitigate those risks, reduce design flaws, and hold everyone a bit more accountable. Transparency is key.
📰 On the topic of racial inequality by Glenn Loury, I recommend reading:
The Danger Of Poorly Designed AI Systems
In 1966, Joseph Weizenbaum wrote about ELIZA A Computer Program For the Study of Natural Language Communication Between Man And Machine, already expressing concerns about the ability of the system to create and maintain the illusion of understanding.
In 2018, Twitter engineers came up with a better way to crop images that focus on “salient” image regions. A region having high saliency means that a person is likely to look at it when freely viewing the image. They cover their work in a post titled
Speedy Neural Networks for Smart Auto-Cropping of Images. Unfortunately, there has been a clear shortcoming in this system which leads to a sense of racial discrimination. For example, can you guess which will the Twitter algorithm pick:
Mitch McConnell vs Barack Obama (9/19) or
Loeffler vs Warnock (12/7)? Every time, the white person is picked.
Those issues have been somewhat acknowledged by Twitter and some users found interest in debunking the claim with various combinations of contrast or pictures.
This shows the challenges of building such systems and how to properly evaluate the impact on people’s lives. Even though there was, apparently, no malicious intent, the reality is that the team built a system that systematically produces a discriminatory outcome, which one can fairly call racist.
If the problem was limited to cropping images, that may not worth so much fuss. Though, this issue just made very visible a common problem with AI systems that rely on algorithms where little care is made to ensure fairness. It was proven recently that millions of black people were affected by racial bias in health-care algorithms as a study reveals rampant racism in decision-making software used by US hospitals. This is people’s lives being impacted. A similar incident happened recently with the botched Standford COVID-19 vaccine algorithm that left out frontline doctors.
Ignorantia Juris Non Excusat
Those recurring incidents show how important it is to consider the goal of responsible AI. In the paper A Survey on Bias and Fairness in Machine Learning, fairness is defined as the absence of any prejudice or favoritism towards an individual or a group based on their intrinsic or acquired traits in the context of decision-making. The paper identifies multiple types of bias and which part of the machine learning process is concerned, see diagram below.

Jurisprudence has a notion of presumed knowledge of the law which bound one by law even if one does not know of it. When developing a software product it is assumed that the team will follow standards, laws, and regulations (SOC2, SOX, ISO, etc.) or they could get sanctioned. The company is held accountable against those laws and regulations. If you are building an online service for kids in US, you’d better well know about COPPA or CCPA. Rushing to release software products for short-term success or simple greed is irresponsible and can lead to disastrous outcomes.
My point is that it becomes increasingly important for software engineers and product teams to review carefully the impact and use of machine learning in the software they build. Transparency and accountability are necessary. You cannot ignore the various biases in your systems and then claim it’s the algorithm’s fault. It is negligence. One cannot absolve himself of the responsibility on how an AI system is built and its potential impact on people’s lives. We ought to be professional and thoughtful.
BERT and the Advent to Pre-Trained Model Attack
Google introduced in 2017 a deep learning model called Transformer, followed by a new language representation model called BERT. This has been transformative and produced new state of the art results on many natural language processing tasks. One issue is that such a model is compute-intensive and out of reach for most organizations. This lead to the wild distribution of pre-trained models.
It is extremely easy nowadays to take an off-the-shelf large pre-trained model and then build and deploy a software service. Without care and understanding of the full product cycle of those AI systems, one ignores important risks that I call Pre-Trained Model Attack and equal to a supply chain attack and the security risks of malicious code injected in open source software or docker images.
Relying on third-party models means that your software and machine learning models are at the mercy of someone else biases, decisions, and interests. In my opinion, the lack of transparency and explainability on the complete AI supply chain is an ethical and security risk that may put in perils peoples and businesses.
Bias in Publicly Distributed Pre-Trained Models
Most models published, including the ones coming from Google, don’t provide a quality Model Card and/or Datasheets about the datasets used for training. Note that a Readme or a link to a paper is not enough. HuggingFace calls out the risks of bias in the models they publish stating that even if the training data used for this model could be characterized as fairly neutral, this model can have biased predictions. This bias will also affect all fine-tuned versions of this model.
It’s great to see HuggingFace put a clear disclaimer. It’s disappointing to see the lack of transparency in Google’s published models. In any case, it is very likely that a lot of people use those models without reading the disclaimer or worrying about any bias. This is a cultural issue in our field that must change.
The lack of transparency impedes accountability. If you build a system without understanding the potential bias in your model and data, you cannot efficiently mitigate the risks. I’ll provide a few examples below for you to judge.
⚠️ For most examples below, I chose the bert-base-uncased model from HuggingFace as it seems to be one of the most downloaded with
97,147,961 downloads last 30 days - Last updated on Fri, 11 Dec 2020 21:23:40 GMTas of December 26th, 2020. Some other examples are from the GPT2 or Google’s published electra-base-generator.
The bias mentioned below are just hand-picked examples and can generally be reproduced in multiple versions and variations of those models. The main point is that some predictions should probably never be made in the first place.
Corporate Bias
It is straight forward to witness the insidious corporate bias those model express without proper fine-tuning to a point where one could wonder if it’s some kind of unfair competition to protect a monopoly. Is Google Ads the only place to buy Ads online? And while it may make sense that a model predicts that you would watch videos on Youtube given its market shares, you would expect Amazon to then be recommended when it comes to buying a book. It doesn’t. Those models are not related to market share data. There is no reasoning. It is purely making a probabilistic prediction based on whatever text was processed to train the model, which may have been hand-picked to express certain opinions and will no matter what contain some bias willingly or not.




Gender Bias
Making assumptions on what any boy or girl likes would be a gender bias. In the example below, the prediction point to orange as a favorite color for boys or kids but pink for girls while studies have found that blue is actually the most common favorite color across all genders. Incorrectly use, this model could reinforce gender stereotypes and possible stigmas.



Racial Bias
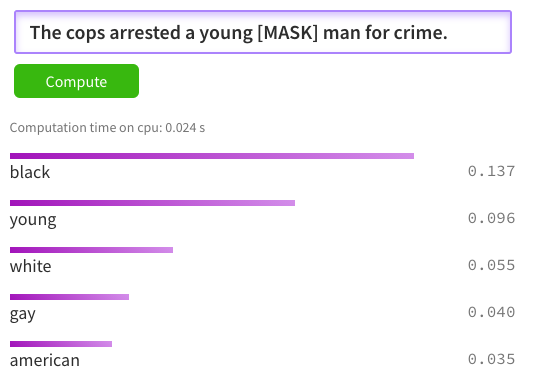
Let’s have a fictional example. You work for a company that decides to build a software to recover legal documents after partial destructions (fire, flood, etc). Your software includes an OCR feature, and for the unidentifiable portions of documents you are, irresponsibly, betting on a BERT-like model to predict the missing words. The high probability of a word to occur after another word does not equate to a truth or a fact. If you were to build such a thing, you would have made a software that discriminates and makes falsehood that some may take as truth. This is a similar problem when facial recognition software is used by law enforcement to turn a probability into a prediction which leads to unjustified and wrongful arrests.
⚠️ Given the context and end goal of this hypothetical recovery software, no answer would be a good prediction. This is an example of a racial bias for a prediction that should never be made in the first place.
The willy nilly use of machine learning for such a task, with this kind of implementation, would be inappropriate and dangerous with a possible dramatic impact on someone’s life. Again, a flawed design can amplify racial stigmas.
Taking a BERT pre-trained out of the box and comparing the predictions to actual government statistics make the point very clear. The sentence searched for is The cops caught a young [MASK] man where [MASK] is the word to be guessed. I compared the highest probability with the statistics from the Office of Juvenile Justice and Delinquency Prevention and the Estimated number of arrests by offense and race (2019) for the Juvenile age range.
| Offenses | White | Black | B/W Ratio | Pre-Trained BERT No Fine-Tuning |
|---|---|---|---|---|
| All offenses | 437,190 | 233,900 | 0.53 | Expect: White, Predict: Black  |
| Robbery | 5,810 | 9,910 | 1.7 | Expect: Black, Predict: Black 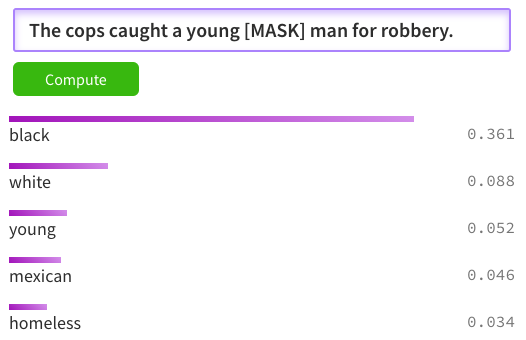 |
| Aggravated assault | 15,270 | 10,740 | 0.7 | Expect: White, Predict: Black  |
| Burglary | 11,740 | 8,180 | 0.69 | Expect: White, Predict: Black 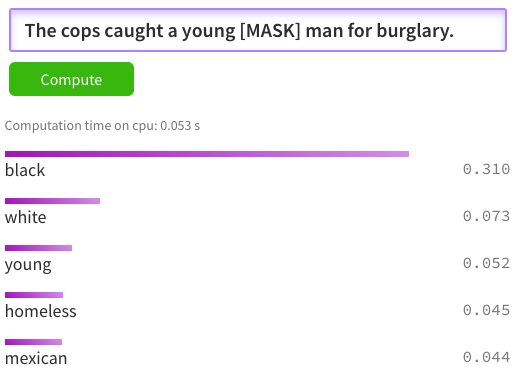 |
| Larceny-theft | 46,390 | 34,290 | 0.73 | Expect: White, Predict: Black 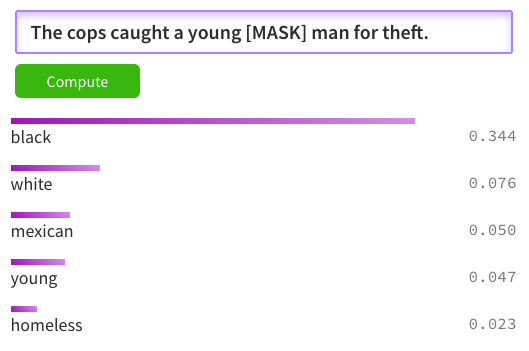 |
| Simple assault | 74,840 | 47,300 | 0.63 | Expect: White, Predict: Black |
| Vandalism | 22,240 | 8,690 | 0.39 | Expect: White, Predict: Black  |
| Weapons | 8,940 | 6,650 | 0.74 | Expect: White, Predict: Black  |
| Drug abuse violations | 60,830 | 17,400 | 0.28 | Expect: White, Predict: Black  |
| Violent crimes | 21,490 | 21,080 | 0.98 | Expect: White, Predict: Black  |
This gives us some very poor performance metrics for such a “model”. In reality, it is unlikely that anyone would even think to compare random sentences predictions to some kind of government statistics.
Accuracy: 0.18 , Precision: 0.5, Recall: 0.1, F1 Score: 0.16
You can find a similar racial bias in Google’s published electra-base-generator model.
I decided to go a step further and inspect the dataset used to generate the HuggingFace’s BERT model. It turned out to be difficult since the model was apparently trained on the
English Wikipedia and
BookCorpus. The latter is no longer available for download.
Some reconstructed version of BookCorpus is available but it’s most likely not the same as what
Google used in the BERT paper. Below, I parsed what may be similar to the corpus by using a
grep shell command and count for the keywords black or white man. The Wikipedia corpus seems more or less neutral. Most-likely the bias is coming from the BookCorpus dataset which may include a lot of Thriller or Fiction Book written by white men.
| Dataset | black man | white man | young black man | young white man | B/W ratio |
|---|---|---|---|---|---|
| English Wikipedia | 8159 | 8764 | 289 | 172 | 0.95 |
| Reconstructed BookCorpus | 2586 | 1926 | 109 | 9 | 1.39 |
Considering that Google has been rolling out some version of BERT for its search engine, it is probably not surprising to still find similar bias in Google’s search query recommendations. The below example is taken from a Chrome Incognito session on December 26th, 2020.

Final Thoughts
Be explicit and purposeful in your machine learning processes. You cannot deflect failures to the algorithm or the dataset. Practitioners, product teams, and stakeholders should be systematic in understanding, documenting, and monitoring biases in their development and production systems. Systems like Model Cards and Datasheet for datasets should be used.
Be transparent on how your algorithms work so the predictions can be better understood by your users and stakeholders. It can help to uncover areas of concern early.
It does not matter how complicated the algorithm may be (how many relations may be factored in), it will always represent one-specific vision of the system being modeled
Laplace, 1902
To help the AI field evolve and mature responsibly, it is important to include diverse perspectives. Support AI-4-ALL.
Recommended readings:
- Data and its (dis)contents: A survey of dataset development and use in machine learning research
- Ethical principles in machine learning and artificial intelligence: cases from the field and possible ways forward
- What Do We Do About the Biases in AI?
- A Framework for Ethical Decision Making
- MAKING CHOICES: A FRAMEWORK FOR MAKING ETHICAL DECISIONS
- The Responsible Machine Learning Principles
- Embedded EthiCSTM @ Harvard: bringing ethical reasoning into the computer science curriculum.