This post is a re-post from my original LinkedIn post.
Over the past few years I had the unique opportunity to see a start-up, TubeMogul, going through hyper-growth, an IPO, and an acquisition by a fortune 500, Adobe. In this journey, I was exposed to a lot of technical challenges, and I work on systems at an astonishing scale, i.e. over 350 billions real-time bidding request a day. It allowed me to build some strong personal opinions on the role of an SRE and how they can help transform an organization. I’m lucky enough to work with a talented team of SRE that keep pushing the limits of innovation while executing through chaos.
As I flew back from the ML for DevOps (Houston) summit that Adobe sponsored, I took the time to reflect on some of the ways our SRE teams excel in their job and how they leverage machine learning and self-healing principle to scale their day-to-day operations.
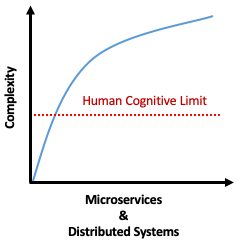
I.T. Systems, with the broad adoption of public and private cloud, get more complex over time. The hyper-adoption of micro-services and the increase of loosely coupled distributed systems are an obvious factor, though you can see how IoT devices, edge computing, and al. can factor into the mix.
Point being, it is increasingly difficult for a single individual to understand the space in which a product evolve and live. One cannot assume knowing it all. Humans quickly reach their cognitive limit. So, how do SRE overcome this limit? Below is my take on the top 5 machine learning and self-healing techniques used by SRE to scale and operate increasingly complex environments.
1. Build Self-Healing Services
Self-healing, sometime called auto-remediation, is not a software program, and it is not a tool. It is a process. SRE have the unique opportunity to improve their service reliability by implementing self-healing capability into the service. In my opinion, self-healing has a limited impact at the host/device level, but it can quickly benefit your quality of service when done at a larger scale like data center failure, region failover, etc.
Self-Healing: Automatic discovery, and correction of faults; automatically applying all necessary actions to bring system back to normal operation. Wikipedia, Self-management
Use Case: Adobe SRE recently won the Best Disruptive Idea Award for our paper “ Use of Self-Healing Techniques to Improve the Reliability of a Dynamic and Geo-Distributed Ad Delivery Service” at the 2018 IEEE International Symposium on Software Reliability Engineering.
2. Release Pipeline That Facilitates Self-Healing
Yes, cloud services may provide the core infrastructure needed to automate and ensure redundancy of your systems. Though, it’s of a little value if your product and engineering teams can’t leverage it and iterate quickly with it. You need to have the fundamentals in place, so every engineer doesn’t have to reinvent the wheel for every new app or code push. Providing infrastructure that facilitates the adoption of self-healing through your application is critical. SRE always look at enabling faster product velocity while preserving service quality. A system infrastructure with a release pipeline that automates deployment, rollback, health check, and can scale your services easily would provide all the fundamentals needed to empower engineers to build a resilient application. Think GitOps.
Use Case: Adobe SREs support a large number of Kubernetes clusters across our clouds. For example, our Adobe Advertising Cloud SRE team provide a Kubernetes infrastructure that enabled our engineers and data scientist to develop, test, and release quickly to production new machine learning models through a GitOps workflow.
3. Forecasting & Capacity Planning
Capacity Planning can be daunting work. Even with some auto-scaling infrastructure, there is always a point where you need to forecast where your system will be in few months (or days), what will be your next peak, and how it may impact your overall cost efficiency or your dependent systems.
There are quite a few ways for an SRE to forecast time series:
- Naive Method: used the last period data point to forecast the next one. Generally used for comparison with other models.
- Simple Average: estimate the next period value based on the average of all the previous data points.
- Moving Average: estimate the next period value based on the average of only the last few data points. It can be more effective than it sounds.
- Simple Exponential Smoothing (SES): forecast use weighted average where the weight decrease as the observations come further from the past.
- Holt’s Linear Trend: extend exponential smoothing to allow forecasting of data with a trend - Holt (1957). As it tends to over-forecast, you can “dampen” the trend by using a Damped Holt Method - Gardner & McKenzie (1985).
- Holt-Winters: include seasonality in your forecast. Very valuable for most time series observed by an SRE. It can be easily added to any graph using Prometheus, Graphite, etc.
- Autoregressive Integrated Moving Average (ARIMA): while the previous models look at trend and seasonality, ARIMA (and Seasonal ARIMA) try to separate the signal from the noise.
- Long short-term memory (LSTM): a recurrent neural network (RNN) that can learn long sequences of observations based on multiple input vectors.
This is just to name a few, though they are commonly used to build dashboards and drive capacity planning efforts.
Use Case: Adobe SRE, for our Adobe Analytics service, leverage an RNN model to forecast highly seasonal customer traffic and drive capacity planning of its on-prem infrastructure.
4. Anomaly Detection and Self-Healing
Let’s clear the confusion now. Threshold alert is not anomaly detection. SRE will look at implementing a cluster analysis algorithm to classify the outliers. It can be either supervised, unsupervised, or semi-supervised depending on the scenario.
In data mining, anomaly detection (also outlier detection) is the identification of rare items, events or observations which raise suspicions by differing significantly from the majority of the data. Wikipedia, Anomaly detection
With appropriate anomaly detection, SRE can implement self-healing technique into their systems that will allow pro-active capacity planning or correction to ensure service availability. It goes beyond action based on time series and pre-defined static threshold.
Use Case: Adobe SRE, for its Adobe Experience Platform, use forecasting and machine learning techniques to define in real-time dynamic thresholds that drive corrective actions to prevent incidents or capacity issues.
5. Risk Classification Of Changes Plugged into a CI/CD pipeline
As I mentioned earlier, systems are getting more complicated and hard to understand while a large part of the SRE role is to embrace and manage risk. It becomes increasingly tricky to understand the impact of every changes or test for every scenario before they are “canary released” in production. At the 2018 ISSRE Keynotes “When Software Reliability Engineering Meets Artificial Intelligence” professor Michael R. Lyu, from the Chinese University of Hong-Kong, presented novel technique to correlate user feedbacks comments to code regression. SRE can leverage their CI/CD pipeline to add a lot of safety-net and increase understanding of risks. By leveraging natural language processing, a lot of information can be extracted from Git commit, Tickets, and ChangeLogs. That information can be used to forecast and classify the risk of a change before it goes to production and then provide a recommendation on corrective action or require additional peer-review.
Use Case: Adobe SRE reviewed over 40,000 change logs in the past year to build a model that can predict with over 95% accuracy the risk of an incident due to change while keeping the noise of change notification below 5%. See below slide for more details.
See my presentation slides on SlideShare: Improving Adobe Experience Cloud Services Dependability with Machine Learning
Beyond the Basics
It doesn’t stop here. I can see a lot more opportunities for SRE to leverage ML to improve services dependability at scale and reduce toil. Few examples that come to my mind:
- ML model to identify drifts in a configuration that can lead to a fault
- ML model to automate the tuning of systems configuration and reach optimal performances
- ML model to detect UX regressions or degradation by integrating with RUM data
- ML model to simplify and automate incident troubleshooting and root cause analysis etc.
What are your thoughts? Where do you see the future of ML in an SRE world?


